
Shellmates club
blog

Behind the scenes of CAPTCHA verification across different versions (Turning behavior into code)
Touami Mohammed - Web Exploitation
Published on : 9/21/2022
Web Exploitation
Cybersecurity
Introduction:
Whether you’re signing up for a new account, buying tickets to an upcoming football game or simply clicking a link that a friend sent you, you’ve most likely come across a section under the name "CAPTCHA Verification".
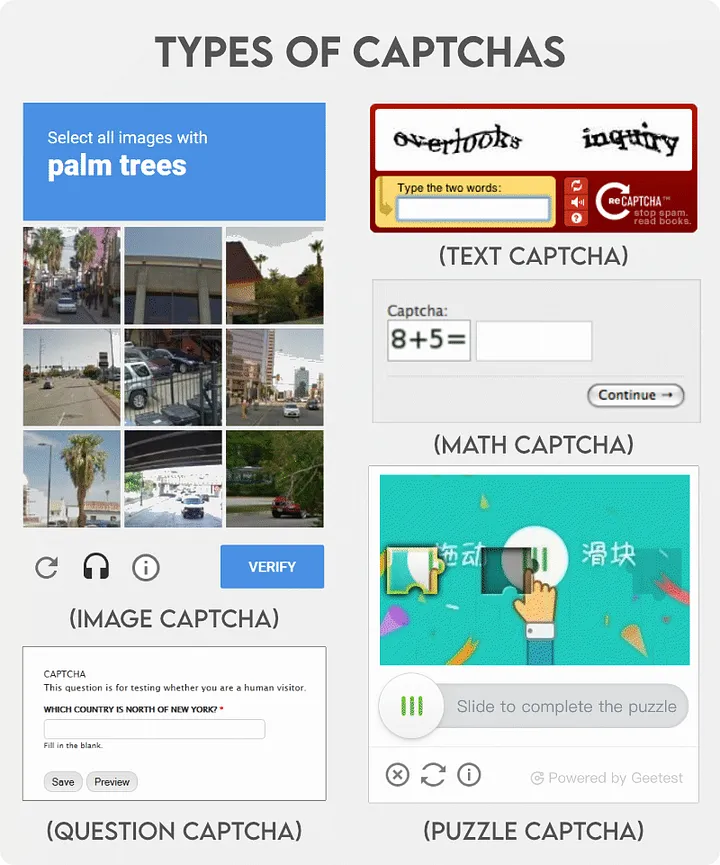
Some common CAPTCHA types
It might ask you to retype the text displayed on your screen, select the correct boxes according to a given question, or as of late, simply clicking a checkbox. The questions might change from website to another but the goal is always the same, ensuring the traffic that the website is receiving is from humans and not bots.
Bot attacks:
When we hear of cyber security breaches we generally think the culprit is a hacker, but nine times out of ten it is another computer (commonly called a bot) that is responsible. Someone can write up a script telling the computer to keep repeating a certain task (usually targeting a website) without the person having to step in at any moment.
The way these bots are being used varies quite a bit, they can be used to buy out multiple tickets at an upcoming event, create multiple accounts on some platform and spam users with fake messages, or even try and over-saturate some website’s servers in an attempt to crash them or overfill their database.
The reason these attacks are dangerous (and often unstoppable) is because they target large scale, high traffic websites which means you can’t setup a manual traffic verification system with humans in charge, so the only solution is have another computer check the traffic, which is where CAPTCHA comes into play.
Before making any comparisons:
Understanding the behavior of a bot in comparison to a human is essential before building any CAPTCHA model, you have to ensure the test you’re creating is impossible for bots to solve but still easy for humans to do, and here lies the difficulty, on one hand you have people that use the web coming from all across the world, speaking different languages and having different ideologies, on the other hand you have bots which are only as smart as the "hacker" programmed them to be.

reCAPTCHA V3 in different languages
These tests have to ensure two main qualities:
- Unique, easy to find answer for humans regardless of language, background or age.
- Hard to understand problem for bots, but not for humans (image or voice recognition, trivia questions…)
Trying to understand how a CAPTCHA model works behind the scenes isn’t as easy as it seems, since their source code is generally kept secret by their makers, after all, if you figure out how they work, you’re only helping cyber criminals bypass them more easily.
Generally research is done on different models by launching several bot attacks and seeing how each model responds, this helps researchers get an idea of what criteria the CAPTCHA model uses to verify you and what are its limits, for example this research paper about Hacking Google reCAPTCHA v3 using Reinforcement Learning.
We also have to remember that we will not be comparing the performance nor the security of CAPTCHA versions but rather their working principal and the code that makes them run.
The modus operandi of CAPTCHA:
Let’s get down to the main topic now, we will be looking at the most popular CAPTCHA models since their first outing in 1997, and analyzing how each model works at determining humans from bots.
1. Automated filter system: First ideas arise
Back in the 90s, the leading search engine at the time, AltaVista, had a manual URL submission system where users could submit websites to be shown in the search results, and in 1997 they suffered their first ever bot attack where a number of users abused this URL submission feature in an attempt to skew the website’s result ranking algorithm.

AltaVista’s search interface, 1997
The company’s chief scientist, Andrei Border, along with his colleagues developed the first automated filter system that was able to distinguish between humans and bots. They thought of a solution that showed the user a list of letters in a format that the Optical Character Recognition (OCR) systems at the time couldn’t recognize.
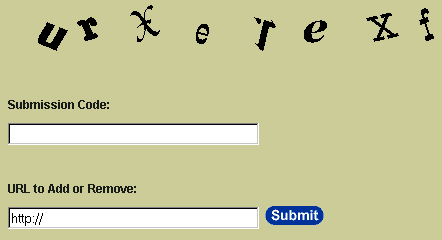
AltaVista’s bot verification system
When the user clicks on Add URL, a random set of letters are chosen on the server side which are paired with their images, these images later get skewed, blurred or distorted (as shown in the image above) and displayed for the user to try and decipher. This system helped the company reduce spam bot submissions by up to 95%.
2. Yahoo’s solution: Chat room chaos
In the year 2000, Luis Von Ahn (founder of Duolingo today), was attending a talk at his university by the chief scientist at Yahoo about 10 Problems Yahoo! couldn’t solve, and one of the problems was on how spam bots were creating millions of accounts on the platform which were used to send fake messages to users over chat rooms.

Yahoo’s spam bot accounts issue (Credit: Vox, YouTube)
Luis and his team thought of a similar system to that implemented by AltaVista back in 1997, displaying text on the screen and having the user retype it in. Except the difference this time around was that the words were harder to distinguish with lines running across them.
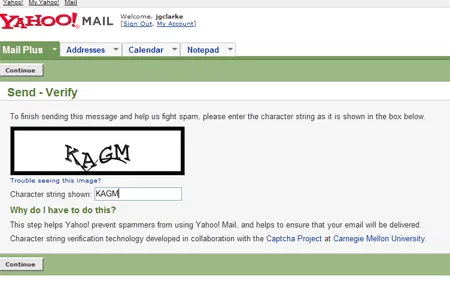
Yahoo’s spam bot prevention system
Still the basic idea was the same, comparing two strings to see if they’re the same or not, the difficulty lied in trying to make the words as distorted as possible but still having them be readable by humans.
Bot_Verification(userInput, correctAnswer) { if(userInput == correctAnswer) { human(); } else { bot(); } }
Pseudocode explaining previous verification systems
Both previous system weren’t called CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) but rather just a bot verification system, it wasn’t until 2003 when Luis decided to officially coin the name.
The Turning test part comes from the fact that the verification is based on the aforementioned test, where a person (called interrogator) is tasked with differentiating between a person and machine simply by analyzing text responses, but in our case the interrogator is a computer hence why it’s described as Automated.
3. reCAPTCHA: The genius behind the system
In 2005, the first iteration of reCAPTCHA was introduced, it worked similarly to previous CAPTCHA models but it integrated a smarter system that helped the machine learn by itself.
The server sends the user an image of two words to decipher, the server knows the answer to the first word (just like previous CAPTCHA), but the second word is taken from an old book or some random New York Times article and the server doesn’t know what it means in text form.

reCAPTCHA verification example
If the user enters the first word correctly the server assumes that he is a human and takes his input of the second word into consideration, the test is given to multiple users and if most of their inputs match, that word is added to the database and used later as a "first word" in the image.
reCAPTCHA(userInput, correctAnswer) { word1, word2 = userInput.split(); if(word1 == correctAnswer) { probably_human(word2); } else { bot(); } } probably_human(word2) { if(word2 == otherInputs) { human(); } else { bot(); } }
Pseudocode explaining reCAPTCHA verification
4. reCAPTCHA by Google: When the giant steps in
Google acquired reCAPTCHA in 2009 in an attempt to secure the text database to itself, their aim was to digitize their scanned books and news archives.
Not only did this help them build a digital library of distorted and blurred words but also allowed them to create new CAPTCHAs using these words without the need for the complicated two word system the original reCAPTCHA model had.
Google had also developed AI models capable of solving CAPTCHAs with an accuracy of up to 99.8%, in comparison, humans success rate at solving the test is on average 33%. Although these models were never made public (for obvious reasons), this still pushed Google to ditch the text recognition model for the next version.
It’s important to note that the text recognition format isn’t considered a complete failure; there are models in recent years that can’t even get close to the accuracy Google achieved in the early 2010s.
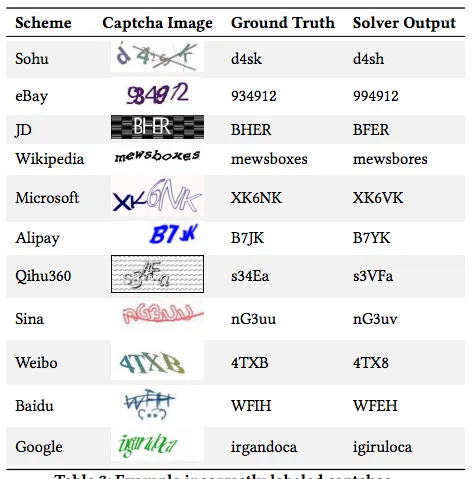
2018 CAPTCHA solver model with incorrect results
5. reCAPTCHA V2: New version incoming
When 2014 came around, Google decided to opt for a new CAPTCHA model, this time implementing pictures from the real world and asking the user to select images containing a certain object (fire hydrant, bus, crosswalk…). It has two formats, one that shows a full image and asks the user to select certain sections of it, and one that shows nine different images and asks you to select multiple of them, but the main idea is the same.
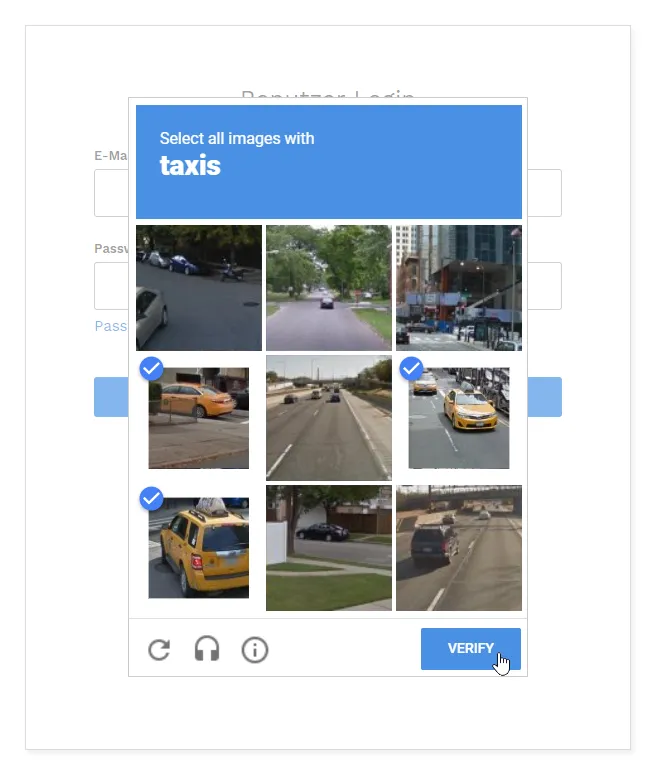
reCAPTCHA V2 example
This model implements the self learning technique used back in 2005; in some of the pictures that are displayed the system knows what objects they contain, but for the majority it doesn’t, so it compares the answers from millions of submissions (that it assumes are correct), and if the user had selected the correct boxes for the images that the system knows the answer to, and also if other users have selected the same images, then the answer is assumed to be correct, or in other words the user is a human not a bot.
The system may be even more complex when taking in consideration that Google can be implementing an AI model to help label the objects in the images, for simplicity we can use the following code abstraction to explain the working method of the CAPTCHA model.
reCAPTCHA_V2(selectedImages[], correctImages[]) { int n = numberOfCorrectAnswers(selectedImages,correctImages) if (n==9) //since there is 9 boxes to select human (); else unsure(selected[mages, correctImages); unsure(selectedImages [], correctImages []) { if (close_enough (selectedImages, correctImages)) human (); else bot (); }
Pseudocode explaining reCAPTCHA V2 verification
The function close_enough() takes a look at the user’s wrong answers and checks if they’re close enough to the actual answer, or in other words, is it really a human error or not (since not everyone is going to answer the CAPTCHA in the same manner).
Another thing that is incredibly interesting about reCAPTCHA V2 is what Google uses it for (aside from spam filtering of course), if you hadn’t noticed yet, almost all of the objects the test asks you to find are road related: cars, trucks, buses, traffic lights, crosswalks… and this is because Google uses the data from the correct answers in order to teach its autonomous vehicles to better recognize objects on the road.
6. noCAPTCHA: But how does it know?
noCAPTCHA example
This CAPTCHA test is the easiest to pass but the hardest to understand, it emerged in the late 2010s and it works on the basis of understanding human behavior. It can be split into three different categories based on their method of work, however they can still be used in conjunction with each other:
Mouse movement tracking: when you open a new session in a website implementing noCAPTCHA, your mouse movement starts getting tracked by a pre-written script, the data gets collected and when you click the check box that says "I’m not a robot", the data gets sent to the server which checks your mouse position during the session and tries to guess whether you’re human or not.
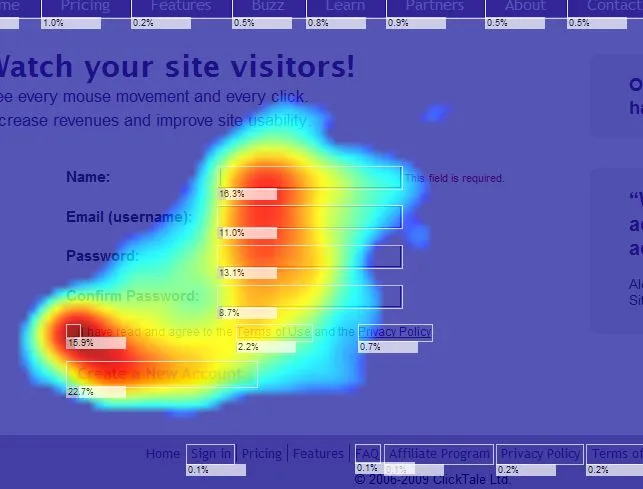
Mouse movement heat-map
The system also collects your mouse movements (speed and direction) which gets used in the verification, generally a bot has fast, direct and linear mouse movement while a human is slower, more jittery and less accurate.
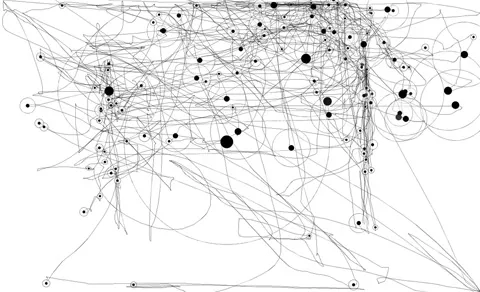
Mouse tracking data
Browser canvas trap detection: another way that is used to determine human behavior on a website is by using HTML and CSS to try and trick the bot into clicking a fake inexistant button, since the bot cannot see the screen and can only read the website’s source code, a fake input element is created that isn’t actually shown on the screen meanwhile the real checkbox is rendered as a div which the user can obviously see. A bot can get tricked into clicking the input button meanwhile a human can only click the real button in the div element.
Network activity: your IP address, cookies history, and other networking data is constantly being sent to the server to try and catch any suspicious activity that might prove you’re a bot, for example using a VPN or a Proxy.
noCAPTCHA may also use other criteria such as device type, browser settings and many other to figure out the nature of the user, all this data is fed through a model in the server that returns what it thinks the user may be.
7. reCAPTCHA V3: Third time lucky
In 2018 Google launched its latest version of the test, reCAPTCHA V3, a more user friendly, precise and easy to implement version of noCAPTCHA, the main feature they offered was a grading system for each activity on the website by how human it seemed, they also offered different analytics to help companies filter the traffic they receive on their websites.

reCAPTCHA V3 grading users’ behavior (Credit: Google Search Central, YouTube)
Conclusion:
Understanding the working mechanism behind CAPTCHA is perceived differently by people in the community, because on one side you are doing research on hard to understand models to help learn how the system works, so that you might contribute your own solution to the CAPTCHA community, but on the other side you are helping spammers improve their bots by showing them how the security system works. In any case, as long as these tests are protected by powerhouse tech companies such as Google there is no need to worry about dangerous spam bot breakouts any time soon.